Cloud Computing Tutorial
Contents

Icebreaker questions¶
Enter your answers in chat or in your own text editor of choice.
Is everyone who wants to be logged into their jupyterhub and have the notebook open?
When you hear the term “cloud computing” what’s the first thing that comes to mind?
What concepts or tools are you hoping to learn more about in this tutorial?
Learning Objectives¶
The difference between code running on your local machine vs a remote environment.
The difference between data hosted by cloud providers, like AWS, and on-prem data centers
The difference between how to access data hosted by NASA DAACs, on-prem, cloud/s3
Cloud computing tools for scaling your science
Key Takeaways¶
At least one tutorial (or tool) to try
Sections¶
Local vs Remote Resources
Data on the Cloud vs On-premise
How to access NASA data
Tools for cloud computing: Brief introduction to Dask
Setup: Getting prepared for what’s coming!!!¶
Each section includes some key learning points and at least 1 exercise.
Configure your screens so you can see both the tutorial and your jupyterhub to follow along.
Let’s all login into https://urs.earthdata.nasa.gov/home before we get started.
The bottom lists many other references for revisiting.
Let’s install some libraries for this tutorial.
1. Local vs Remote Resources¶
❓🤔❓ Question for the group:¶
What’s the difference between running code on your local machine this remote jupyterhub?
As you are probably aware, this code is running on machine somewhere in Amazon Web Services (AWS) land.

What types of resources are available on this machine?¶
CPUs¶
The central processing unit (CPU) or processor, is the unit which performs most of the processing inside a computer. It processes all instructions received by software running on the PC and by other hardware components, and acts as a powerful calculator. Source: techopedia.com
# How many CPUs are running on this machine?
!lscpu | grep ^CPU\(s\):
CPU(s): 2
Memory¶
Computer random access memory (RAM) is one of the most important components in determining your system’s performance. RAM gives applications a place to store and access data on a short-term basis. It stores the information your computer is actively using so that it can be accessed quickly. Source: crucial.com
# How much memory is available?
!free -h
total used free shared buff/cache available
Mem: 6.8Gi 851Mi 4.0Gi 9.0Mi 2.0Gi 5.6Gi
Swap: 4.0Gi 11Mi 4.0Gi
If you’re curious about the difference between free and available memory: https://haydenjames.io/free-vs-available-memory-in-linux
🏋️ Exercise: How many CPUs does your machine have¶
Unless you are using a linux machine, the above commands probably won’t give you what you need.
For MAC users:
sysctl -a | grep cpu | grep hwor https://www.linux.com/training-tutorials/5-commands-checking-memory-usage-linux/For Windows users: https://www.top-password.com/blog/find-number-of-cores-in-your-cpu-on-windows-10/ (Not tested)
❓🤔❓Question for the group¶
When might you want to use a remote machine and when might you want to use your local machine?
2. Data on the Cloud vs On-premise¶
What’s the difference between data hosted on the cloud and on-prem data centers?¶
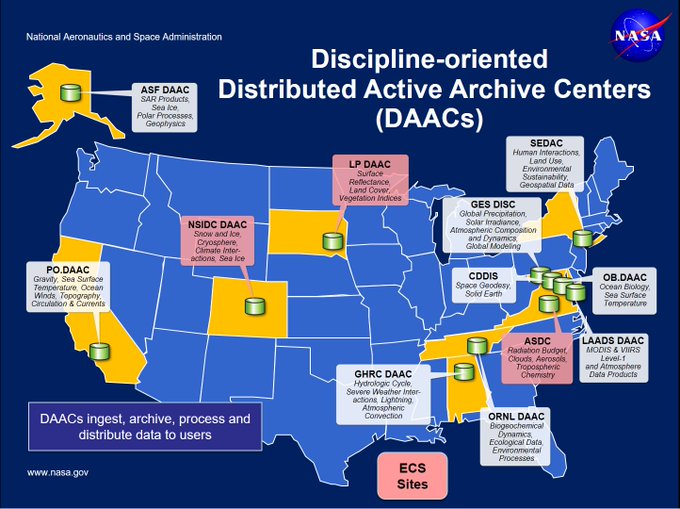
NASA DAACs are in the process of migrating their collections to the “Earthdata Cloud”. At this time, most datasets are still located and accessible “on-premise” from NASA DAACs, while high priority and new datasets are being stored on AWS Simple Storage Service (S3). Given different use cases, you will need to access datasets from NASA DAAC’s as well as on NASA’s Earthdata Cloud (AWS S3).
Datasets are still managed by the DAAC, but the DAAC stores files on AWS S3.
The DAACs’ services will be collocoated in the cloud with the data.
Users are encouraged to access the data collocated in the cloud through AWS computer services (like this jupyterhub!)
🏋️ Exercise¶
Navigate search.earthdata.nasa.gov and search for ICESat-2 and answer the following questions:
Which DAAC hosts ICESat-2 datasets?
Which ICESat-2 datasets are hosted on the AWS Cloud and how can you tell?
What did we learn?¶
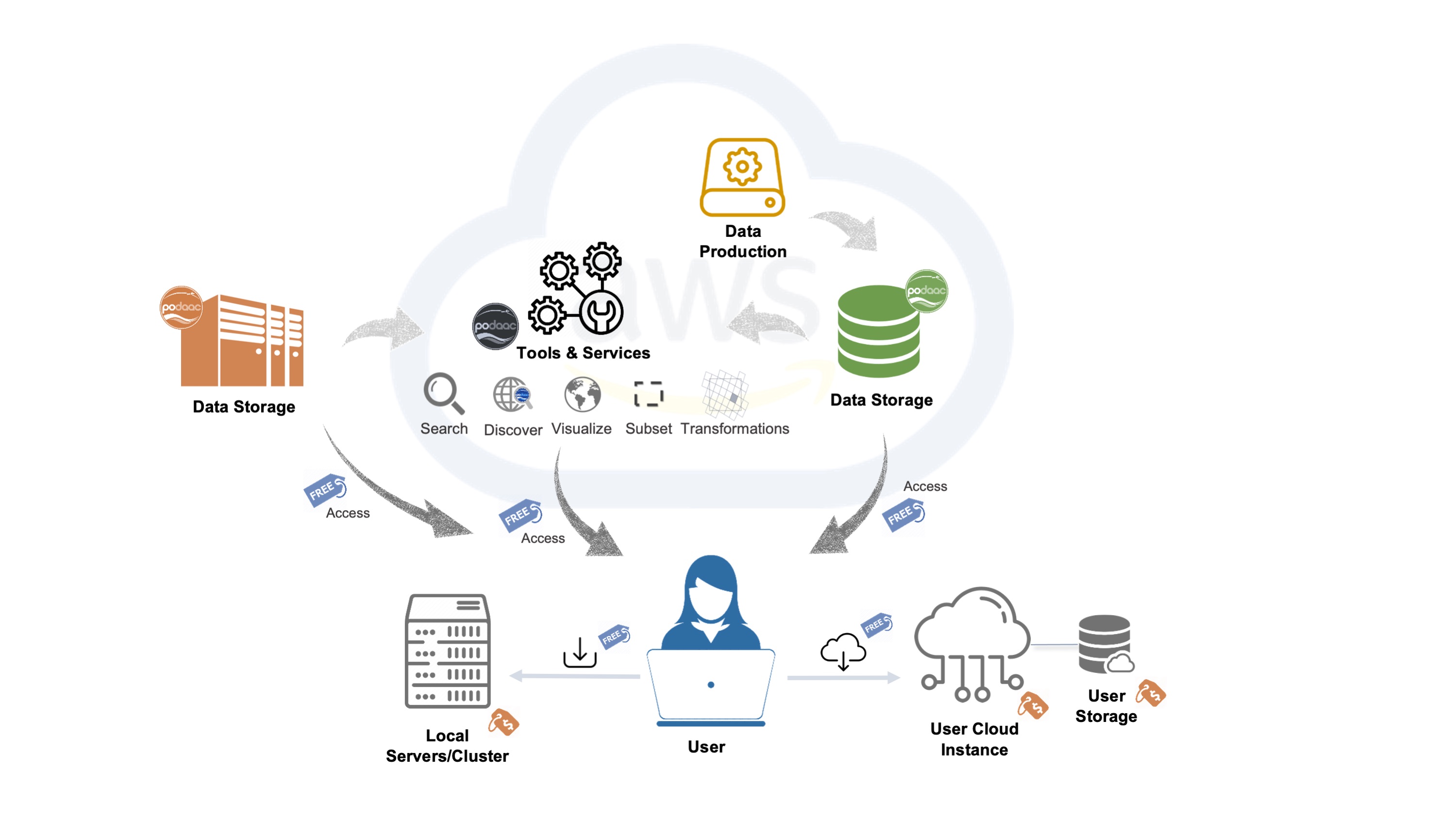
NASA has a new cloud paradigm, which includes data stored both on-premise as well as on the cloud. NASA DAACs are providing services also on AWS.
PO.DAAC has a great diagram for this new paradigm, source https://podaac.jpl.nasa.gov/cloud-datasets/about
Final thought: Other cloud data providers¶
AWS is of course not the only cloud provider and Earthdata can be found on other popular cloud providers.
AWS also has its public data registry Open Data on AWS and its sustainability data initiative with its Registry of Open Data on AWS: Sustainability Data Initiative
3. How to access NASA data¶
How do we access data hosted on-prem and on the cloud? What are some tools we can use?
Earthdata Login for Access¶
NASA uses Earthdata Login to authenticate users requesting data to track usage. You must supply EDL credentials to access all data hosted by NASA. Some data is available to all EDL users and some is restricted.
You can access data from NASA using ~/.netrc files locally which store your EDL credentials.
🏋️ Exercise 1: Access via Earthdata Login using ~/.netrc¶
The Openscapes Tutorial 04. Authentication for NASA Earthdata offers an excellent quick tutorial on how to create a ~/.netrc file.
Exercise: Review the tutorial and answer the following question: Why might you want to be careful running this code in a shared jupyterhub environment?
Takehome exercise: Run through the code on your local machine
🏋️ Exercise 2: Use the earthdata library to access ICESat-2 data “on-premise” at NSIDC¶
Programmatic access of NSIDC data can happen in 2 ways:
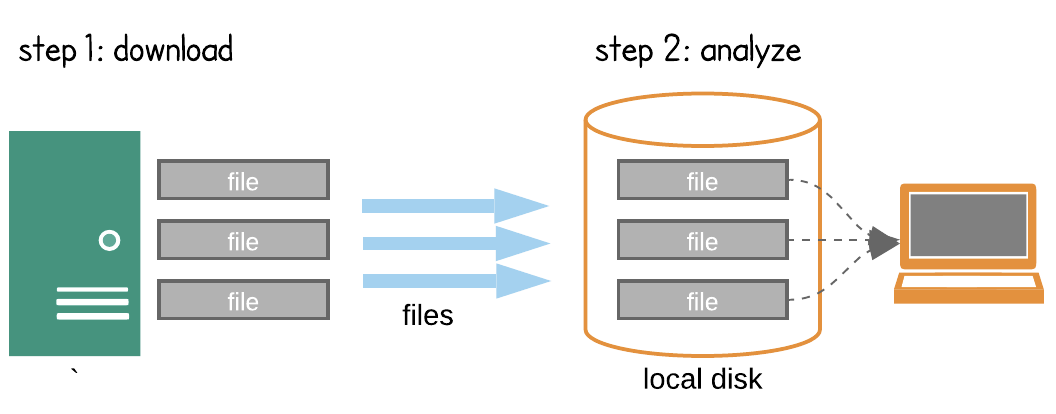
Search -> Download -> Process -> Research
Search -> Process in the cloud -> Research
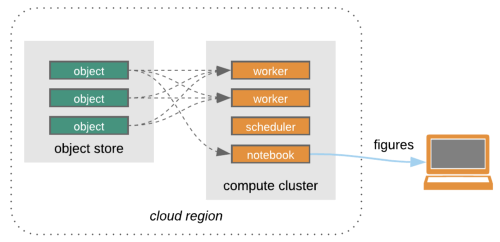
Credit: Open Architecture for scalable cloud-based data analytics. From Abernathey, Ryan (2020): Data Access Modes in Science.
For this exercise, we are going to use NSIDC’s earthdata python library to find and download ATL08 files from NSIDC DAAC via HTTPS.
# Login using earthdata
from earthdata import Auth, DataGranules, DataCollections, Store
import os.path
auth = Auth()
# For Githhub CI, we can use ~/.netrc
if os.path.isfile(os.path.expanduser('~/.netrc')):
auth.login(strategy='netrc')
else:
auth.login(strategy='interactive')
You're now authenticated with NASA Earthdata Login
Earthdata library uses a session so credentials are not stored in files.
auth._session
<earthdata.auth.SessionWithHeaderRedirection at 0x7f86e0811550>
# Find some ICESat-2 ATL08 granules and display them
granules = DataGranules().short_name('ATL08').bounding_box(-10,20,10,50).get(5)
[display(g) for g in granules[0:5]]
Size: 114.3358402252 MB
Spatial: {'HorizontalSpatialDomain': {'Orbit': {'AscendingCrossing': -174.28814360881728, 'StartLatitude': 59.5, 'StartDirection': 'D', 'EndLatitude': 27.0, 'EndDirection': 'D'}}}


Size: 118.2040967941 MB
Spatial: {'HorizontalSpatialDomain': {'Orbit': {'AscendingCrossing': -174.28814360881728, 'StartLatitude': 59.5, 'StartDirection': 'D', 'EndLatitude': 27.0, 'EndDirection': 'D'}}}


Size: 100.266831398 MB
Spatial: {'HorizontalSpatialDomain': {'Orbit': {'AscendingCrossing': -174.28814360881728, 'StartLatitude': 27.0, 'StartDirection': 'D', 'EndLatitude': 0.0, 'EndDirection': 'D'}}}


Size: 103.6830654144 MB
Spatial: {'HorizontalSpatialDomain': {'Orbit': {'AscendingCrossing': -174.28814360881728, 'StartLatitude': 27.0, 'StartDirection': 'D', 'EndLatitude': 0.0, 'EndDirection': 'D'}}}


Size: 131.1225614548 MB
Spatial: {'HorizontalSpatialDomain': {'Orbit': {'AscendingCrossing': -3.243598064031987, 'StartLatitude': 0.0, 'StartDirection': 'A', 'EndLatitude': 27.0, 'EndDirection': 'A'}}}


[None, None, None, None, None]
## Check if these are hosted on the cloud
granules[0].cloud_hosted
False
import glob
## Download some files
atl08_dir = '/tmp/demo-atl08'
store = Store(auth)
store.get(granules[0:3], atl08_dir)
Getting 3 granules, approx download size: 0.33 GB
import h5py
## Open one of them
files = glob.glob(f'{atl08_dir}/*.h5')
ds = h5py.File(files[0], 'r')
ds
<HDF5 file "ATL08_20181014034354_02370106_004_01.h5" (mode r)>
❓🤔❓ Question for the group¶
Which NSIDC data access paradigm does the above code fit into?
🏋️ Exercise 3: Access COG data from S3 using Earthdata Search¶
First I will demonstrate how to navigate to search.earthdata.nasa.gov and search for GEDI data “Available from AWS Cloud”. Select a granule and click the download icon and then AWS S3 Access and “Get AWS S3 Credentials”
To generate S3 credentials programmatically, you can follow the tutorials this was based on:
import boto3
import rasterio as rio
from rasterio.session import AWSSession
import requests
import rioxarray
import os
def get_temp_creds(provider):
return requests.get(s3_cred_endpoint[provider]).json()
s3_cred_endpoint = {
'podaac':'https://archive.podaac.earthdata.nasa.gov/s3credentials',
'gesdisc': 'https://data.gesdisc.earthdata.nasa.gov/s3credentials',
'lpdaac':'https://data.lpdaac.earthdatacloud.nasa.gov/s3credentials',
'ornldaac': 'https://data.ornldaac.earthdata.nasa.gov/s3credentials',
'ghrcdaac': 'https://data.ghrc.earthdata.nasa.gov/s3credentials'
}
if os.path.isfile(os.path.expanduser('~/.netrc')):
# For Githhub CI, we can use ~/.netrc
temp_creds_req = get_temp_creds('lpdaac')
else:
# ADD temporary credentials here
temp_creds_req = {}
session = boto3.Session(aws_access_key_id=temp_creds_req['accessKeyId'],
aws_secret_access_key=temp_creds_req['secretAccessKey'],
aws_session_token=temp_creds_req['sessionToken'],
region_name='us-west-2')
# ADD S3 URL from Earthdata Search here
# Note you want to pick a GeoTIFF for the rioxarray code to work
s3_url = 's3://lp-prod-protected/HLSL30.020/HLS.L30.T58KEB.2022077T225645.v2.0/HLS.L30.T58KEB.2022077T225645.v2.0.SZA.tif'
# NOTE: Using rioxarray assumes you are accessing a GeoTIFF
rio_env = rio.Env(AWSSession(session),
GDAL_DISABLE_READDIR_ON_OPEN='TRUE',
GDAL_HTTP_COOKIEFILE=os.path.expanduser('~/cookies.txt'),
GDAL_HTTP_COOKIEJAR=os.path.expanduser('~/cookies.txt'))
rio_env.__enter__()
da = rioxarray.open_rasterio(s3_url)
da
What did we learn?¶
How to use earthdata library to access datasets
How to use earthdata search to generate credentials
❓🤔❓ Question for the Group¶
When making a request to Earthdata file URLs, how do we know if the data are coming from Earthdata Cloud or on-premise?
Final Thoughts¶
There are a lot of other examples of NASA data access, here are a few examples
4. Tools for cloud computing¶
We’ve spent a lot of time on how to access the data because that’s the first step to taking advantage of cloud compute resources. Once you have developed a way to access the data on the cloud or on-premise, you may be ready to take the next step and scale your workload using a tool like Dask.
Dask is a flexible library for parallel computing in Python. Dask is composed of two parts: Dynamic task scheduling optimized for computation.
https://docs.dask.org/en/stable/
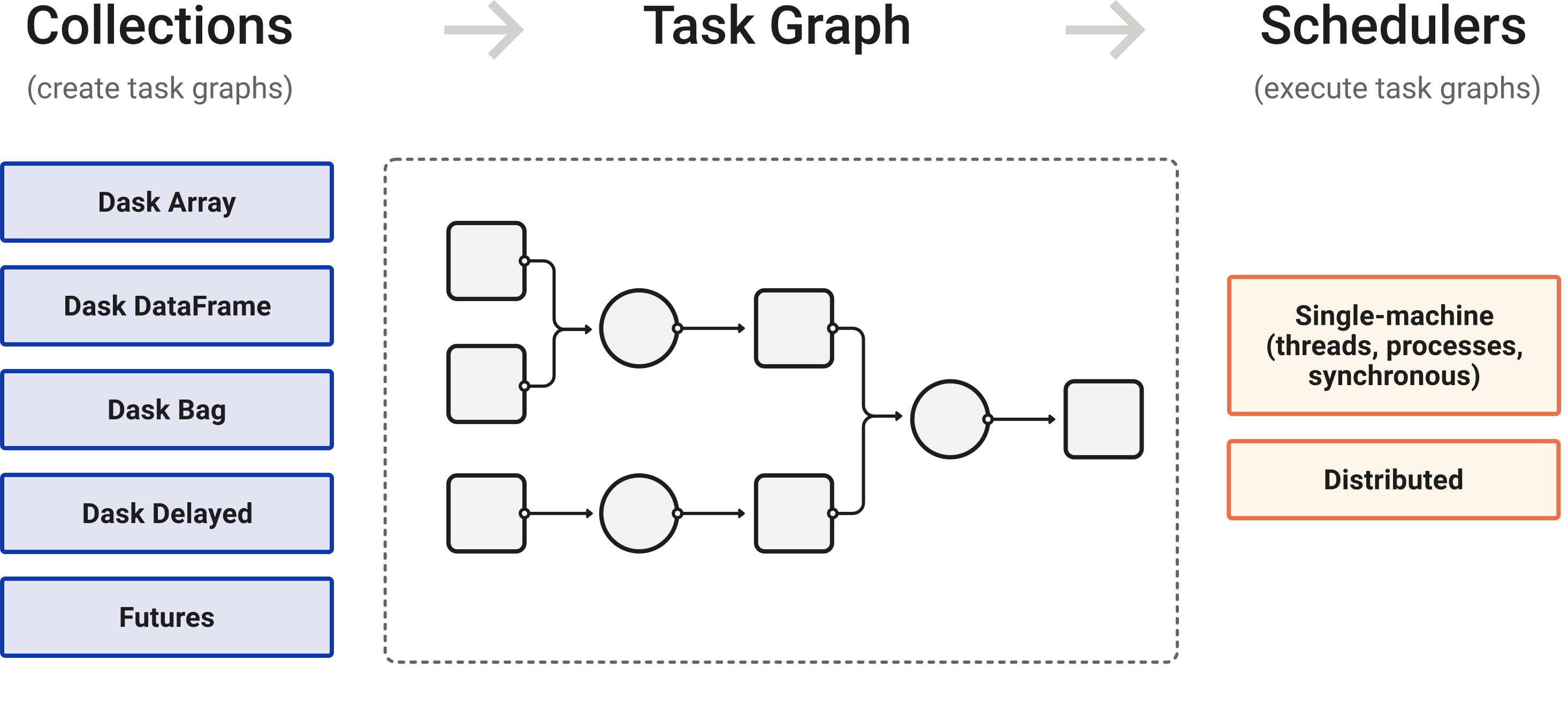
Dask is composed of three parts. “Collections” create “Task Graphs” which are then sent to the “Scheduler” for execution.
🏋️ Exercise - Using Dask to parallelize computing¶
from dask.distributed import Client
client = Client(n_workers=4,
local_directory="/tmp/dask" # local scratch disk space
)
client
Client
Client-85b9ad26-bc4e-11ec-8cc7-000d3a5532a0
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: http://127.0.0.1:8787/status |
Cluster Info
LocalCluster
381f84f1
| Dashboard: http://127.0.0.1:8787/status | Workers: 4 |
| Total threads: 4 | Total memory: 6.78 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-65a1d00c-44ff-4770-9f52-114b79c30094
| Comm: tcp://127.0.0.1:35127 | Workers: 4 |
| Dashboard: http://127.0.0.1:8787/status | Total threads: 4 |
| Started: Just now | Total memory: 6.78 GiB |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:36809 | Total threads: 1 |
| Dashboard: http://127.0.0.1:40411/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:43947 | |
| Local directory: /tmp/dask/dask-worker-space/worker-_ta8evn7 | |
Worker: 1
| Comm: tcp://127.0.0.1:34183 | Total threads: 1 |
| Dashboard: http://127.0.0.1:44433/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:40069 | |
| Local directory: /tmp/dask/dask-worker-space/worker-nck1_coe | |
Worker: 2
| Comm: tcp://127.0.0.1:43331 | Total threads: 1 |
| Dashboard: http://127.0.0.1:46407/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:36049 | |
| Local directory: /tmp/dask/dask-worker-space/worker-eyfm9c03 | |
Worker: 3
| Comm: tcp://127.0.0.1:46201 | Total threads: 1 |
| Dashboard: http://127.0.0.1:32957/status | Memory: 1.70 GiB |
| Nanny: tcp://127.0.0.1:45545 | |
| Local directory: /tmp/dask/dask-worker-space/worker-6qkywasi | |
Basics¶
First let’s make some toy functions, inc and add, that sleep for a while to simulate work. We’ll then time running these functions normally.
In the next section we’ll parallelize this code.
from time import sleep
def inc(x):
sleep(1)
return x + 1
def add(x, y):
sleep(1)
return x + y
%%time
# This takes three seconds to run because we call each
# function sequentially, one after the other
x = inc(1)
y = inc(2)
z = add(x, y)
z
CPU times: user 109 ms, sys: 1.16 ms, total: 110 ms
Wall time: 3 s
5
Parallelize with the dask.delayed decorator¶
Those two increment calls could be called in parallel, because they are totally independent of one-another.
We’ll transform the inc and add functions using the dask.delayed function. When we call the delayed version by passing the arguments, exactly as before, the original function isn’t actually called yet - which is why the cell execution finishes very quickly. Instead, a delayed object is made, which keeps track of the function to call and the arguments to pass to it.
from dask import delayed
%%time
# This runs immediately, all it does is build a graph
x = delayed(inc)(1)
y = delayed(inc)(2)
z = delayed(add)(x, y)
CPU times: user 1.04 ms, sys: 0 ns, total: 1.04 ms
Wall time: 893 µs
This ran immediately, since nothing has really happened yet.
To get the result, call compute. Notice that this runs faster than the original code.
%%time
# This actually runs our computation using a local thread pool
z.compute()
CPU times: user 216 ms, sys: 26.7 ms, total: 242 ms
Wall time: 2.18 s
5
What just happened?¶
The z object is a lazy Delayed object. This object holds everything we need to compute the final result, including references to all of the functions that are required and their inputs and relationship to one-another. We can evaluate the result with .compute() as above or we can visualize the task graph for this value with .visualize().
z
Delayed('add-3477208d-8b6d-4636-93e2-11d0aa7ca6c9')
z.visualize()
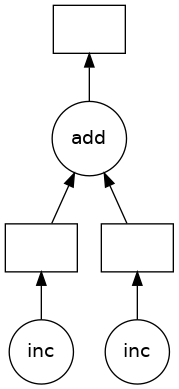
Some questions to consider:
Why did we go from 3s to 2s? Why weren’t we able to parallelize down to 1s?
What would have happened if the inc and add functions didn’t include the sleep(1)? Would Dask still be able to speed up this code?
What if we have multiple outputs or also want to get access to x or y?
Demonstration - Dask¶
We just used local threads to parallelize this operation. What are some other options for running our code?
Dask Gateway provides a way to connect to more than one machine running dask workers.
Dask Gateway provides a secure, multi-tenant server for managing Dask clusters. It allows users to launch and use Dask clusters in a shared, centrally managed cluster environment, without requiring users to have direct access to the underlying cluster backend (e.g. Kubernetes, Hadoop/YARN, HPC Job queues, etc…).
We can see this in action using the ESIP QHub deployment or a Pangeo Hub.
❓🤔❓ Question for the group¶
What makes running code on a dask cluster different from running it in this notebook?
🎁 Bonus¶
If we have time, go through Dask Tutorial from the Pangeo Tutorial Gallery.
Want to learn more?¶
Join the Pangeo and ESIP Cloud Computing Cluster communities
Pangeo is first and foremost a community promoting open, reproducible, and scalable science. This community provides documentation, develops and maintains software, and deploys computing infrastructure to make scientific research and programming easier.
Visit the website or joing the community meetings: Pangeo Community Meetings
Join the ESIP Cloud Computing Cluster for our next Knowledge Sharing Session on Apache Beam for Geospatial data
Cloud computing cluster email list: https://lists.esipfed.org/mailman/listinfo/esip-cloud
ESIP Slack and cloud computing cluster channel: https://bit.ly/3FtX1HV
Resources¶
Examples + Tutorials of cloud computing¶
Collections of tutorials¶
I believe those notebooks will eventually be migrated to Earthdata Cloud Cookbook: Supporting NASA Earth science research teams’ migration to the cloud but that website has placeholders for the content.